
Most detection systems answer questions. Is this IP beaconing? Is this process suspicious? Is this DNS pattern anomalous? The analyst asks, the system responds. Every hunt starts with a human deciding where to look.
But experienced threat hunters don't just answer questions. They generate them. They read a campaign report on Tuesday, notice an unusual DNS pattern on Friday, and connect the two because the pattern rhymes. Nobody asked them to look at that DNS traffic in that way. No alert fired. The connection happened because accumulated knowledge met ongoing observation, and something clicked.
That ability to decide what deserves investigation before anyone asks is what separates reactive from proactive detection. One is called a SOC analyst, the other a threat hunter. Though their ultimate goals are the same — keeping an organization's network safe — their ways of climbing that mountain are fundamentally different.
So when it comes to what's often referred to as the "hunter's intuition", a very interesting design question comes up — can we replicate this nebulous feature with agents? I can't say with full conviction the answer is a resounding yes without feeling like I'm speaking with my marketing hat on instead of my scientific hat, but at the same time I do think there are clear architectural motifs we can employ to increasingly approximate it.
That's what we're exploring with Artifex, the agentic threat hunting system I'm building at AionSec. Concretely: we've built agents that run autonomously on a heartbeat, generate their own hunting hypotheses by cross-referencing live telemetry with a curated knowledge base of past compromises, execute those hunts in the background, and notify the analyst when something crosses a threshold — all without anyone asking them to look.
What Intuition Actually Is

Human threat hunting intuition sounds mystical, but mostly isn't. If we deconstruct it rationally the best we can, it's something like: pattern matching against an accumulated library of past compromises, running continuously against incoming data.
And it's worth remembering that this capacity has very deep roots. We didn't develop pattern matching for cybersecurity — we evolved it to survive. The ancestors who noticed a subtle change in the treeline, who registered that the water tasted slightly different near certain plants, who sensed that a particular silence meant predator rather than calm — those are the ones who lived long enough to pass their genes on. Our brains are, at a fundamental level, threat-detection engines tuned by millions of years of selection pressure. Hunting for adversaries in network telemetry is just the latest expression of a very old capability.
An experienced analyst has seen hundreds of attacks. New telemetry automatically gets compared against that mental library. When something rhymes, not exactly but closely enough, attention snags on it. The matching happens in parallel, unconsciously, the way you recognize a friend's face in a crowd without comparing it against every face you've ever seen.
But it's not purely a function of experience. Some people are genuinely wired for this kind of thinking — they naturally make connections between seemingly unrelated pieces of information, think more laterally, notice patterns where others see noise. As is almost always the case, it's a nature-and-nurture affair: exposure to hundreds of incidents sharpens the skill, but there's an underlying predisposition that varies from person to person. The best hunters tend to have both — the accumulated experience and some innate proclivity for associative reasoning. That's worth being honest about, because it means what we're trying to approximate with agents isn't a simple, fully understood mechanism. There's a humility we should carry into this design challenge.
An agent can't replicate that unconscious parallel matching. But it can do something functionally similar: read telemetry summaries, search a structured library of known compromises, and generate specific hypotheses when current data resonates with past attacks. It's a bit more structured and mechanical, but it runs continuously, never forgets a campaign, and checks every signal against every library entry without getting tired or distracted.
The Hypothesis Pipeline

The process that turns environmental observation into structured hunt proposals follows a deliberate sequence of steps. Each step is constrained: the agent follows a defined pipeline that produces specific, evaluable output.
The pipeline begins with observation. The agent reads telemetry summaries, not raw data. Loading raw telemetry — tens of thousands of connections, process events, DNS queries — would saturate the context, perhaps a few times over, and thus leave no room for pattern matching. Instead, the agent reads aggregated statistics: "12 hosts with beacon scores above 50, 3 new unusual Parent-Child process relationships, 2 hosts with encoded PowerShell execution." Summaries are peripheral vision — the broad contours of what's happening without forcing attention onto every individual event.
From those summaries, the agent identifies signals worth pursuing. Not everything unusual is interesting, and some numbers are always elevated. What matters are changes. Three new LOTS destinations that weren't there last week? That's a delta worth investigating. The agent compares current statistics against historical baselines and picks out the differences that might indicate new activity.
There's another weight in this decision. The agent also reviews its own recent hypothesis history to avoid repeatedly chasing the same thread. Without this check, it would naturally gravitate toward whatever pattern happens to be loudest in the current telemetry — a kind of attentional bias. By tracking what it's already pursued, it can diffuse its coverage across the MITRE ATT&CK tactic framework over time, ensuring that lateral movement doesn't get all the attention just because it's noisy this week while persistence or exfiltration go unexamined.
Those signals then get searched against a structured knowledge base. The library returns matches: a cloud C2 abuse pattern, a specific ransomware incident, possibly others. This is where accumulated knowledge meets current observation.
With library matches in hand, the agent forms a specific, testable hypothesis. Not "something suspicious is happening" but "HOST-A's beaconing to Discord at 60-second intervals using a process named something unusual resembles the cloud C2 abuse pattern seen in the recent campaigns by a known APT." Specificity matters — a vague hypothesis can't be tested, can't be refuted, and can't teach the calibration system anything useful.
Finally, the agent outputs a structured directive specifying which detection skills to run, against which scope, at what priority. The directive enters a queue alongside human-directed work, prioritized against the current workload.
A constraint worth highlighting: the agent that generates hypotheses is never the agent that acts on them. Mixing generation and execution would mean loading both the knowledge library and distilled telemetry into the same reasoning context, which not only saturates context, but diffuses attention. A team of specialized agents working together will always outperform a single Jack-of-All-Trades agent.
The Always-On Hunter
The pipeline described above doesn't run when an analyst clicks a button. It runs on its own.
In Artifex, we set aside a dedicated portion of resources for autonomous hunting. According to a configurable heartbeat, the hypothesis agent wakes up on its own, reads the current telemetry summaries, searches the knowledge base, and decides whether anything in the current environment rhymes with anything it knows about past compromises. If it forms a hypothesis that meets its own confidence threshold, it submits a hunt directive to the queue. That directive gets executed when resources are available, always at lower priority than anything a human explicitly asked for.
This architectural motif — a heartbeat-driven autonomous loop running in the background — was inspired by OpenClaw, a personal AI assistant framework built by Pete Steinberger. What makes OpenClaw feel like an always-on agent isn't any single mechanism, but the combination of scheduled execution, periodic monitoring, and event-driven triggers working in concert. We adapted that pattern for threat hunting: instead of checking email and reading messages, our heartbeat checks telemetry and reads the Grimoire — our curated library of real-world compromise case studies.
The key design decision is what happens when the agent finds something. If a hunt produces findings that cross a severity threshold, Artifex notifies the analyst and has a structured report waiting in their queue. The analyst didn't ask for this investigation. Nobody filed a ticket. The system noticed something on its own, investigated it, and brought the results to the analyst's attention — much like a junior hunter who independently noticed something odd in the logs and wrote it up before the morning briefing.
Most of these autonomous hunts won't find a threat. But here's the thing — and this is something David Bianco's PEAK framework articulates well — the value of a threat hunt was never just about finding threats. Every hunt, regardless of outcome, can strengthen an organization's defensive posture. An agent that hunts for lateral movement and finds nothing might instead discover a misconfiguration, a gap in logging coverage, or the absence of a detection rule that should exist. Even a completely clean result has value: it records that a specific tactic was investigated in this environment and nothing was found, which means subsequent hunts — whether human or autonomous — can focus their attention elsewhere instead of retreading the same ground.
This matters especially for an always-on system. Over dozens of cycles, the autonomous hunter builds a cumulative map of what's been checked, what's missing, and where the gaps are. The occasional threat discovery is the headline, but the steady accumulation of defensive improvements is where most of the long-term value lives.
What Makes This Different From Alerting

Traditional alerting is reactive by design. Rules fire when conditions are met. The direction of information flow is always system-to-human: something happened, here's an alert.
Autonomous hypothesis generation reverses this. The agent proactively examines the environment, compares it against known attack patterns, and proposes investigations that nobody asked for. The direction is knowledge-to-environment: here's what we know about attacks, does any of it match what we're seeing?
This reversal matters because it catches the threats that rules miss. An adversary that operates between the rules — just below the beacon threshold, just outside the signature match, using a technique combination nobody wrote a rule for — evades the entire detection surface.
The hypothesis agent doesn't need a pre-written rule. It needs a knowledge base that describes how adversaries operate and environmental observations to compare against. When something rhymes — a suspicious destination combined with regular connection intervals on a host that never exhibited this pattern before — the agent proposes the investigation. No rule existed for this combination. The agent noticed it because it was comparing against accumulated knowledge, not a static rule set.
This is what moves it closer to intuition than detection. Detection answers pre-defined questions. What we're building with Artifex attempts to generate new ones — not with the same richness or instinct a human brings, but through a disciplined approximation of the same underlying process.
The Learning Loop

Static hypothesis generation is useful but limited. What transforms it into an improving system is the feedback loop from outcomes back to calibration.
When an investigation produces a verdict — true positive, false positive, inconclusive — that outcome feeds back into the system. The calibration mechanism tracks actual hit rates by confidence level. If high-confidence hypotheses are only hitting at 10% instead of 30%, something is wrong with what the agent considers "high confidence." If low-confidence hypotheses are hitting at 15%, the agent is being too conservative.
The feedback also flows into the knowledge base itself. When a hypothesis grounded in a specific campaign pattern produces a true positive, that pattern is reinforced. When the same pattern consistently produces false positives, the entry gains context about what benign activity mimics it. Over time, existing entries get sharper and more nuanced.
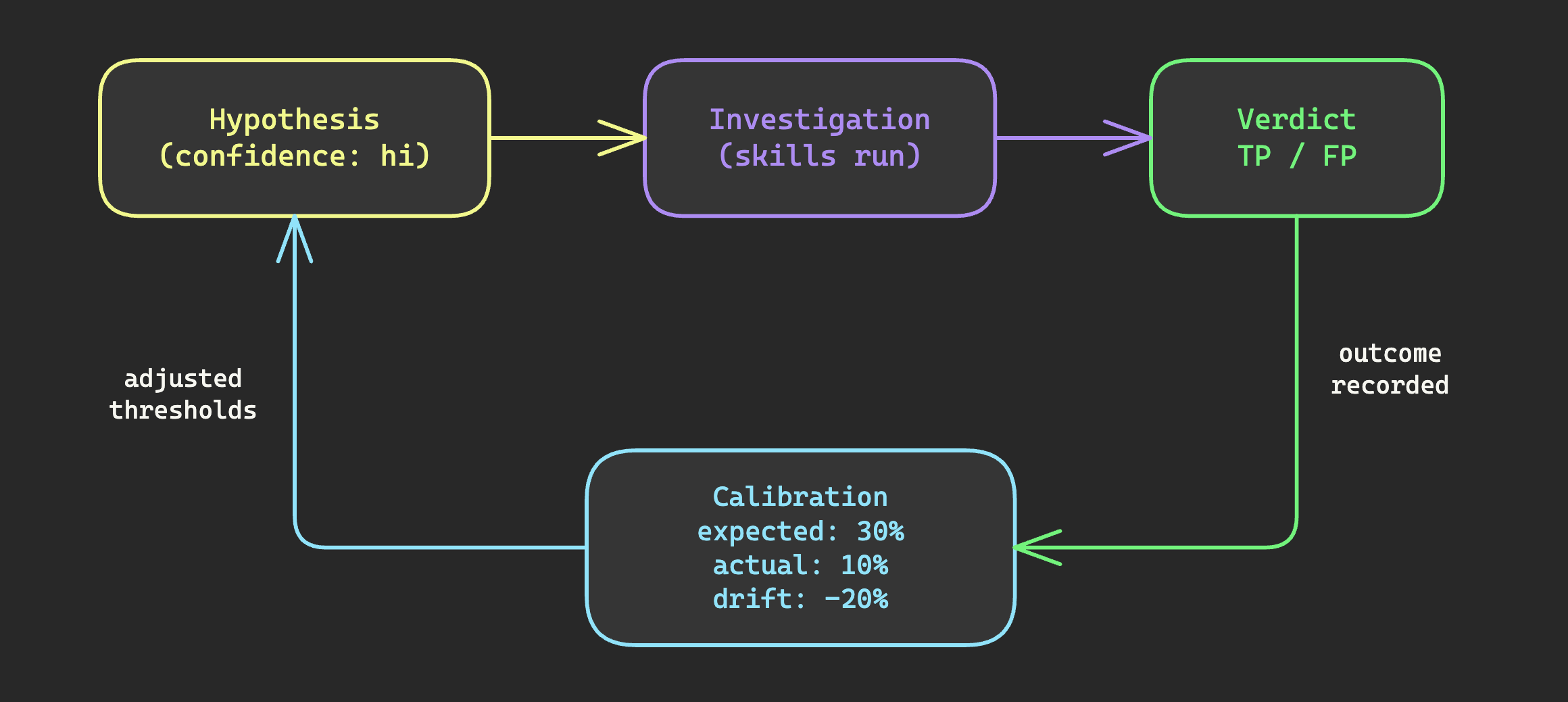
This is the difference between a system that ships and one that improves. With the feedback loop, every verdict teaches the system something about its own calibration, about which patterns matter in this specific environment, and about which signals are genuinely predictive versus environmentally noisy.
The loop takes time to produce useful statistics. You need dozens of outcomes per confidence level before the numbers mean anything. But even tracking from the start gives visibility into whether the system is well-calibrated or drifting.