
You've probably tried it. Dumped a chunk of raw logs into an agent's context and asked it to find threats.
Maybe Zeek connection logs. Maybe a Sysmon export. A few hundred lines, maybe a few thousand.
The results looked impressive at first. The agent identified "suspicious" patterns, flagged some IPs, maybe even constructed a narrative about lateral movement or data exfiltration. It sounded confident. It sounded specific.
And most of it was wrong.
Not wrong in an obvious way. Wrong in the way that wastes hours — plausible-sounding conclusions built on coincidence, not evidence. This is what happens when you feed raw telemetry to AI agents. The agent produces output that looks like analysis but is actually spurious correlation dressed up in security vocabulary.
There's a design principle that prevents this, and it changes how you think about building agentic security systems: distill before you deduce. Deterministic preprocessing must sit in front of every agent. Raw data is the enemy of good reasoning.
Why raw logs break agent reasoning

It's tempting to think that bigger context windows and smarter models will eventually solve this. Just give the agent more data and let it figure things out. But the problem isn't capacity. It's the nature of the task.
There are three specific failure modes when agents reason over raw telemetry, and none of them implicitly go away with better models.
The first is spurious correlation. A PowerShell process launches at 2:47am. A DNS query to an uncommon domain happens at 2:48am. An outbound HTTPS connection starts at 2:49am. Fed raw logs, the agent connects these into a story: "the adversary executed a staging script and established C2 communication." It sounds coherent. But those three events might have no actual relationship. The agent is optimizing for narrative coherence, not evidentiary validity. It finds stories because stories are what language models produce.
The second is the absence of statistical grounding. Determining whether a connection pattern is periodic, actual beaconing, requires computing inter-connection durations, fitting distributions, and measuring jitter consistency. These are computational operations, not reasoning operations. An agent asked whether a connection "looks like a beacon" is guessing. A scoring algorithm computing the coefficient of variation against interval data is measuring. There's a real difference between reasoning and calculating, and raw log analysis requires both. Agents can only do one.
The third is non-reproducibility. Ask the same agent the same question about the same logs twice. You'll get different answers. Different patterns flagged, different narratives constructed, different confidence levels. This isn't a flaw — it's how probabilistic models work. But it means raw-log analysis by agents isn't auditable. You can't trace a conclusion back to a deterministic process. You can't reproduce a finding to verify it. In security work, where findings lead to actions with real consequences, that's disqualifying.
These aren't edge cases. They're the default behavior when agents encounter raw telemetry. Not because agents are broken, but because this isn't what they're for. Asking an agent to compute statistics over raw logs is using the wrong tool for the job — and it obscures the things agents actually do exceptionally well.
What distillation actually means
Not model distillation — we're not training a smaller model to mimic a larger one. This is data distillation: transforming an unbounded investigation surface into a bounded, scored set of entry points.
Here's what that looks like concretely:
| Before distillation | After distillation |
|---|---|
| 350,000 connection events | 7 beacon candidates with scores |
| 200,000 DNS queries | 12 DNS anomaly candidates |
| Unbounded investigation surface | Ranked entry points with evidence trails |
| Every question starts with a table scan | Every question starts with a scored candidate |
That first line is worth sitting with. A 50,000-to-1 distillation ratio. Not by throwing data away, but by computing features that capture what matters and discarding what doesn't. It's just adding an abstracted interpretive layer so we don't mistake the trees for the forest — nothing revolutionary.
A deterministic preprocessing layer ingests raw telemetry and does the work that deterministic code does best: parsing events into a unified schema, normalizing field names across sources (Sysmon calls it DestinationIp, Zeek calls it id.resp_h — after harmonization, they're both dest_ip), deduplicating redundant events, correlating network connections with endpoint processes, computing statistical baselines, and scoring patterns against detection logic.
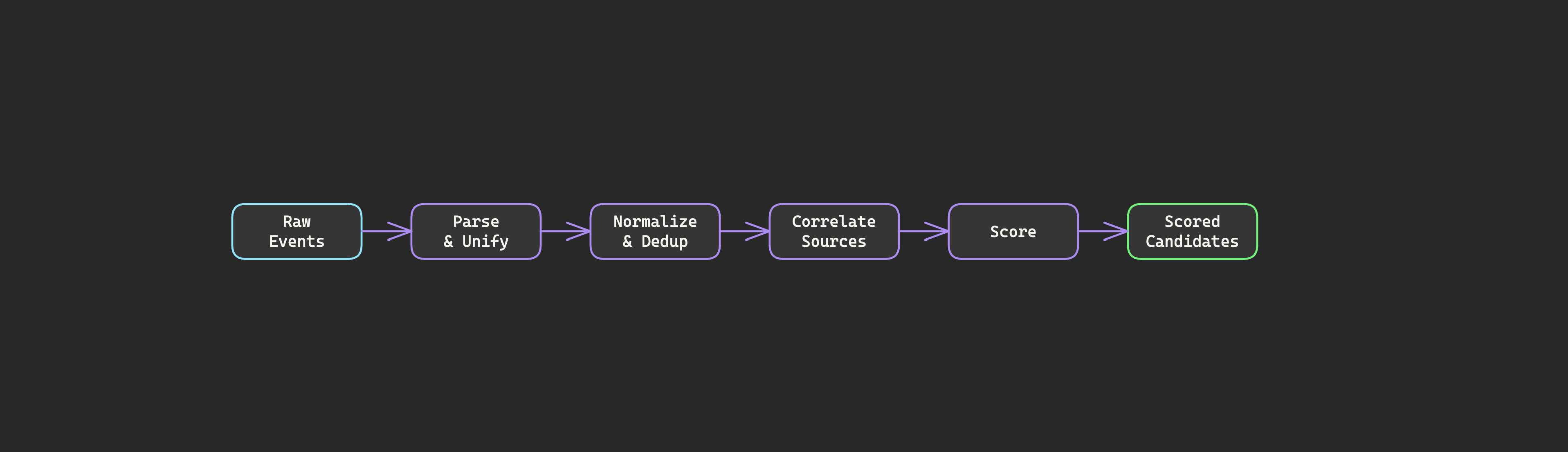
None of this requires reasoning. It requires fast, reliable data wrangling at scale. Deterministic code excels at exactly this.
The output isn't a summary. It's a set of candidates or findings — each one represents a specific pattern that matched detection criteria, with a score and the evidence trail that produced it. A beacon candidate doesn't just say "suspicious connection." It says: this source-destination pair, with this connection count over this time window, with this regularity score based on these interval statistics, with this jitter profile etc.
An agent reasoning over 7 beacon candidates with scores and evidence operates in a completely different mode than an agent reasoning over 500,000 raw connection logs.
What distillation preserves

There's a natural concern that distillation loses detail. If you're reducing 500,000 events to 7 candidates, what happens to the other 499,993?
Nothing. They're still there.
When the preprocessing layer computes a beacon candidate, the raw connection events that produced it remain accessible. The candidate is a pointer into the data, not a replacement for it — they are fundamentally different layers of abstraction. An agent that wants to investigate a high-scoring candidate can drill down to every connection event that contributed to the score, examine individual timestamps, check payload sizes, inspect TLS certificate details.
This is the design choice that matters: distillation adds a layer of analysis on top of raw data without removing the raw data. The candidate tells you where to focus. The events tell you what happened. The score tells you how urgently you should care.
Distillation, when done correctly, directs attention while preserving context.
What distillation adds
Distillation isn't just about summarizing, it's about interweaving data so that analytical artifacts and insights naturally emerge.
Scoring
Scoring is the most obvious one. Raw connection logs contain timestamps and byte counts. Distillation computes derived features: inter-arrival time distributions, periodicity scores, jitter measurements, payload size consistency. A beacon candidate arrives with a regularity score. A score of 0.95 with 2% jitter demands immediate attention. A score of 0.4 with 35% jitter probably represents scheduled software updates. This ranking routes attention to the highest-value candidates first — without the agent having to compute statistics it isn't equipped to compute.
Cross-correlation
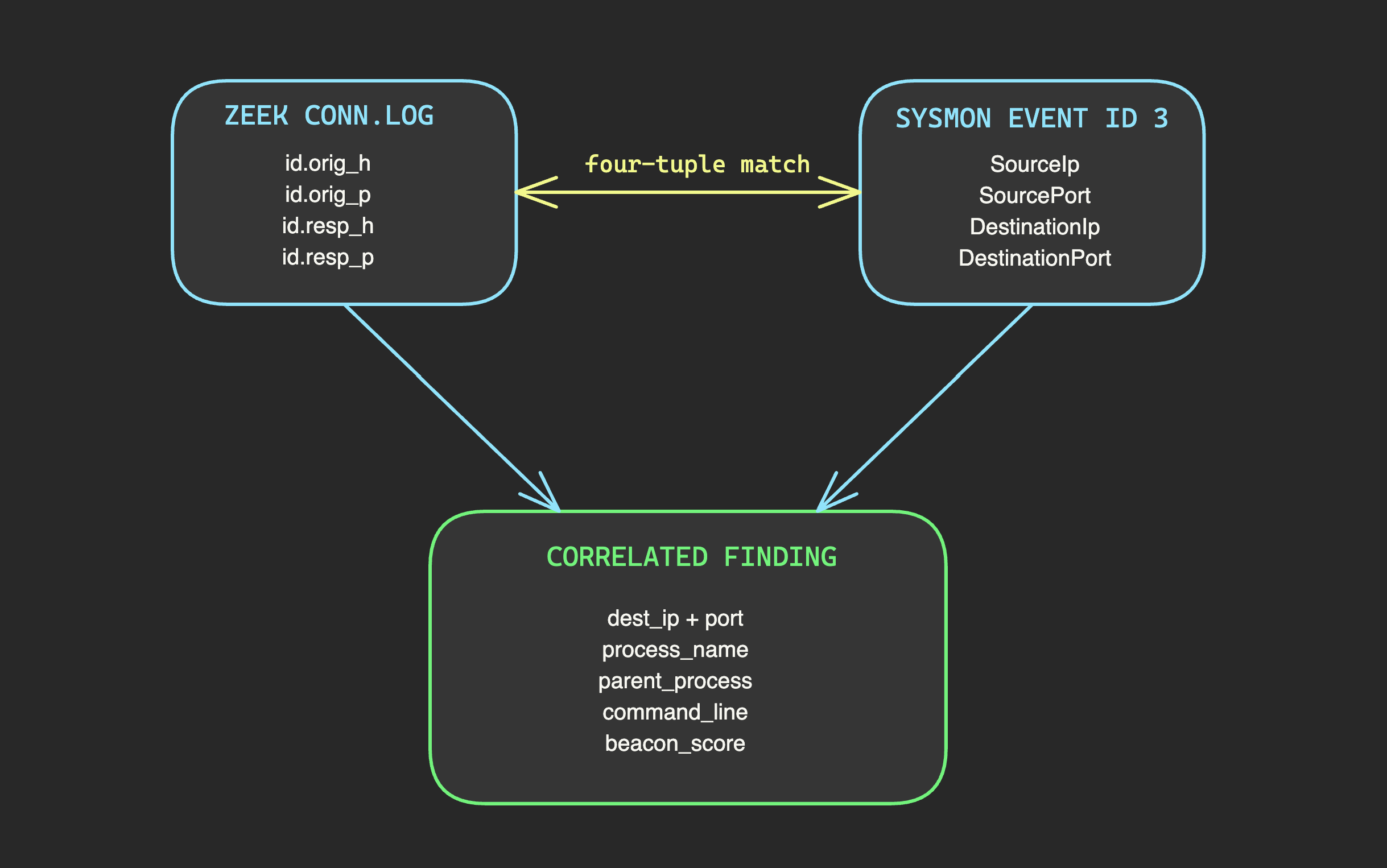
Cross-source correlation is another. A network connection and an endpoint process are logged by different sensors, in different formats, with different identifiers. Distillation correlates them: this beacon candidate corresponds to this process on this host, which was spawned by this parent process. Neither network nor endpoint telemetry alone can answer "which process made this connection and what else did that process do?" The correlated view can. This is deterministic four-tuple matching — source IP, source port, destination IP, destination port — linking Zeek connection logs to Sysmon network events. No reasoning required. Pure data joining. But the result transforms what agents can reason about.
Statistical interpretation
Statistical features are where things get interesting. Jitter-trap detection is a good example. Sophisticated adversaries add random jitter to their beacon timing so it doesn't look perfectly periodic. A 60-second beacon becomes 58, 63, 57, 62 seconds. But adversary-generated jitter is often uniformly distributed within a tight band, which is statistically distinct from genuine human-driven variation. The preprocessing layer computes this. It measures whether the jitter pattern looks artificially random. The jitter itself becomes a detection signal — but only if someone computes the statistics. An agent looking at raw timestamps would never catch this.
Scores as routing functions

There's a distinction in how to interpret the scores that distillation produces that's easy to miss.
A beacon score of 0.92 does not mean "this is 92% likely to be a beacon." It means: among all source-destination pairs in this dataset, this one exhibits the strongest periodic characteristics, and you should look at it first.
Scores are routing functions, not truth functions. They prioritize analyst attention. They tell you where to investigate, not what you'll find when you get there. This matters because treating scores as probabilities leads to overconfidence — "the system says 92% chance of C2" — when the score is actually saying "this is the most interesting pattern in your data right now."
For agents, this framing changes a lot. An agent working with scored candidates doesn't need to evaluate whether something is suspicious from scratch. It already knows what's most worth investigating and can focus its reasoning on the harder questions: Does this candidate fit a known attack pattern? Is there corroborating evidence from other detection types? What's the broader context on this host?
The agent's reasoning quality goes up because it's reasoning about the right things, not because it got smarter. You've distilled the decision space from "find something interesting in 500,000 events" to "evaluate whether this high-scoring candidate represents a real threat." Those are very different tasks, and agents are much better at the second one.
The evidence tier system
Once you accept that distillation must precede deduction, a natural architecture emerges. Think of your data in three tiers, each with different properties and different governance rules.
Tier 1 is events. Raw telemetry. Immutable. Ground truth. One event per log entry — a single process creation, a single DNS query, a single network connection. Events don't tell you what's suspicious. They tell you what happened.
Tier 2 is candidates. Deterministic analytics output. Each candidate is composed of many events (tens to thousands), carries a score, and is typed by detection method. Candidates answer "what looks suspicious?" They're pre-computed on a recurring schedule by deterministic code. Same events always produce the same candidates with the same scores.
Tier 3 is interpretations. Agent reasoning and human analysis. Narratives, hypotheses, verdict recommendations. This is where AI adds value — synthesizing across candidates, checking against threat intelligence, building attack chain narratives, assessing whether multiple findings tell a coherent story.
The governance rule that holds this together: Tier 3 never invalidates Tier 1. An agent can propose that a beacon candidate is part of a C2 chain. It can argue that the timing pattern matches a known APT group's toolkit. But it cannot override the fact that the connection events exist with specific timestamps and specific byte counts. Interpretations organize and prioritize evidence. They don't create or destroy it.
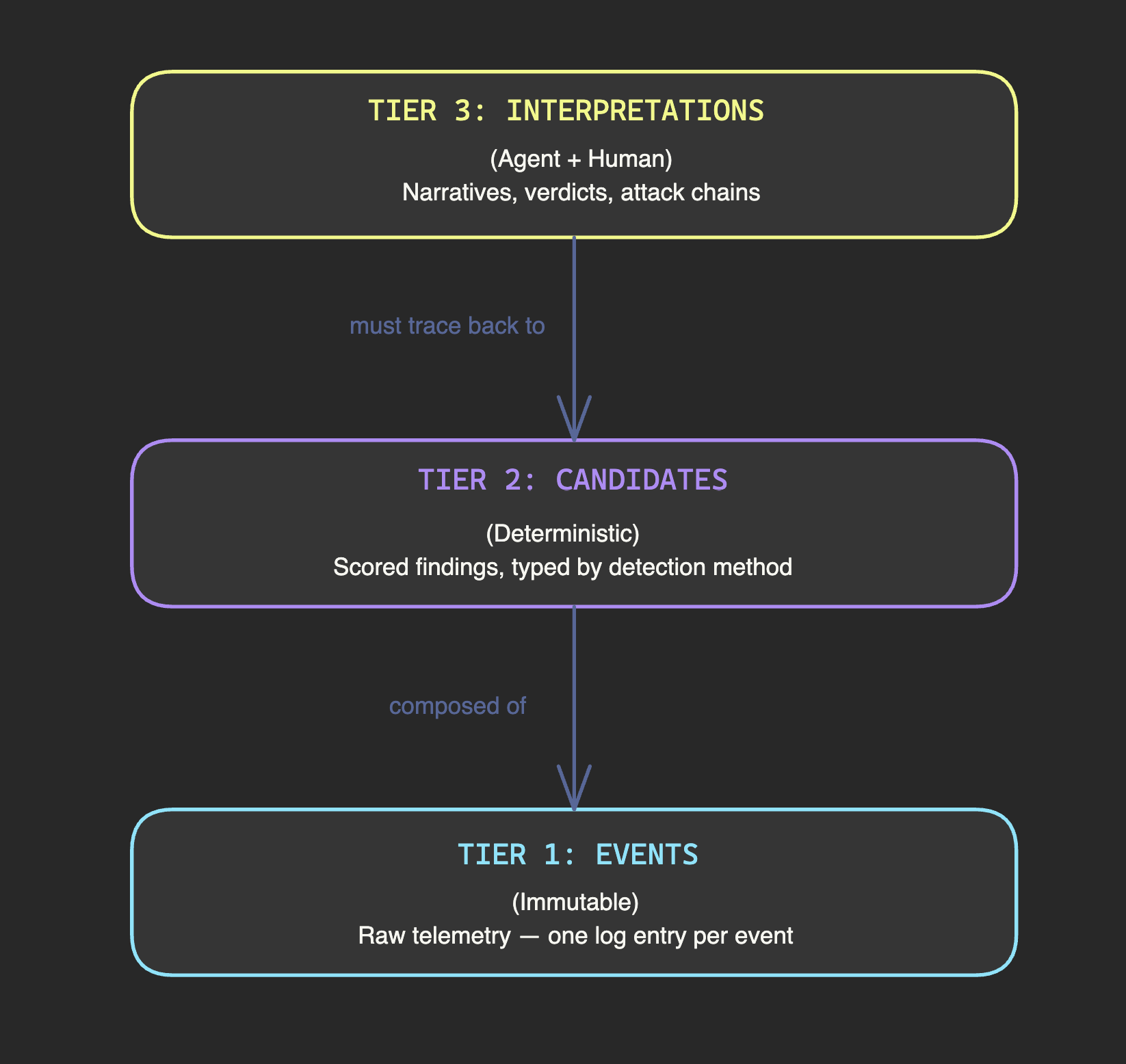
This hierarchy protects against the most dangerous failure mode in AI-assisted security: a confident-sounding narrative that lacks evidentiary support. Every interpretive claim must trace back through candidates to events. If it can't, the interpretation is speculation, regardless of how convincing it sounds.
Token efficiency is reasoning quality

There's an economic argument for distillation that's also a quality argument. They're the same argument.
Every token an agent spends on raw log data is a token it can't spend on reasoning. Context windows are finite. When an agent writes SQL queries against raw event tables, each query consumes tokens. Complex joins and aggregations eat substantial context. When the agent needs to run multiple queries to correlate data, those tokens add up fast. And every token spent on data retrieval is context that's no longer available for analysis.
Pre-computed candidates flip this entirely. The agent makes a single API call and gets back a compact JSON response: seven candidates, each with a score, a time window, connection statistics, and correlation data. Minimal tokens consumed. Maximum context available for the work that actually requires intelligence — interpreting the findings, checking against known attack patterns, reasoning about what to investigate next.
This isn't just an efficiency win. An agent with 80% of its context consumed by raw log data will produce worse analysis than an agent with 5% of its context consumed by pre-scored candidates and 75% available for reasoning. The difference shows up as the gap between an agent that hallucinates patterns in noise and an agent that evaluates real signals with full analytical depth.
The boundary that doesn't move

Context windows will get larger. Models will get smarter. The temptation will be to revisit this principle — maybe now we can just feed the agent raw logs and let it figure things out?
No. The boundary between deterministic preprocessing and agent reasoning is a design principle, not a workaround for current limitations.
Even with a million-token context window, you still don't want an agent computing jitter statistics. That's a math problem with a correct answer, and deterministic code will always solve it faster and more reliably than a language model.
Even with perfect reasoning capability, you still don't want an agent constructing narratives from uncorrelated events. The failure mode isn't insufficient intelligence. It's insufficient evidence structure. A smarter agent builds more convincing hallucinations, not fewer, when the underlying data doesn't constrain what stories are possible.
The preprocessing layer isn't compensating for weak AI. It's doing work that belongs in deterministic code regardless of how capable the AI becomes. Computing statistics. Normalizing schemas. Correlating events across sources. Scoring patterns. Maintaining evidence trails. This is infrastructure — the kind that's reliable and reproducible and auditable — and it's what makes agent reasoning trustworthy rather than performative.
Think of it this way: an agent isn't an algorithm. It's closer to a coworker. You wouldn't hand a security analyst a table with 500,000 connection entries and say "compute the coefficient of variation on the inter-arrival times." That's not what analysts do. You'd ask for their read on a situation, their interpretation of ambiguous evidence, their judgment about what a pattern means in context. Agents work the same way. Don't ask them to calculate. Ask them to reason, interpret, and build narrative around evidence that's already been structured. Use the right tool for the right job.
Raw data is AI's enemy not because AI is weak, but because raw data is the wrong input for the job AI actually does well.